论文链接:https://arxiv.org/pdf/2510.18234
代码链接:http://github.com/deepseek-ai/DeepSeek-OCR
摘要
我们提出 DeepSeek-OCR,作为对利用光学二维映射压缩长上下文可行性的初步探索。DeepSeek-OCR 由两个组件构成:DeepEncoder 和解码器 DeepSeek3B-MoE-A570M。具体而言,DeepEncoder 作为核心引擎,旨在高分辨率输入下保持较低的激活值,同时实现高压缩比,从而确保视觉 token 数量达到最优且易于管理。实验表明,当文本 token 数量在视觉 token 数量的 10 倍以内(即压缩比 < 10×)时,该模型可以达到 97% 的解码(OCR)精度。即使压缩比达到 20×,OCR 精度仍然保持在 60% 左右。这表明该模型在历史长上下文压缩和 LLM 中的记忆遗忘机制等研究领域具有巨大的应用潜力。此外,DeepSeek-OCR 也展现出很高的实用价值。在 OmniDocBench 测试中,DeepSeek-OCR 仅使用 100 个视觉 token 就超越了 GOT-OCR2.0(每页 256 个 token),并且在使用不到 800 个视觉 token 的情况下也优于 MinerU2.0(平均每页 6000 多个 token)。在生产环境中,DeepSeek-OCR 每天可以生成 20 万页以上的 LLM/VLM 训练数据(单台 A100-40G 即可完成)。代码和模型权重可在 http://github.com/deepseek-ai/DeepSeek-OCR 公开获取。
1.介绍
当前的大语言模型(LLM)在处理长文本内容时面临着巨大的计算挑战,因为其计算量与序列长度呈二次方关系。我们探索了一种潜在的解决方案:利用视觉模态作为文本信息的高效压缩媒介。包含文档文本的单张图像可以用比等效数字文本少得多的 token 来表示丰富的信息,这表明通过视觉 token 进行光学压缩可以实现更高的压缩比。
这一洞见促使我们从 LLM 的角度重新审视视觉语言模型(VLM),重点关注视觉编码器如何提升 LLM 处理文本信息的效率,而非人类擅长的基本视觉问答(VQA)。光学字符识别(OCR)任务作为连接视觉和语言的中间模态,为这种视觉文本压缩范式提供了一个理想的测试平台,因为它们在视觉和文本表征之间建立了一种自然的压缩-解压缩映射,同时提供了量化的评估指标。
因此,我们提出了 DeepSeek-OCR,这是一个 VLM 用于视觉文本压缩的初步概念验证方案,旨在实现高效的视觉文本压缩。我们的工作主要有三点贡献:
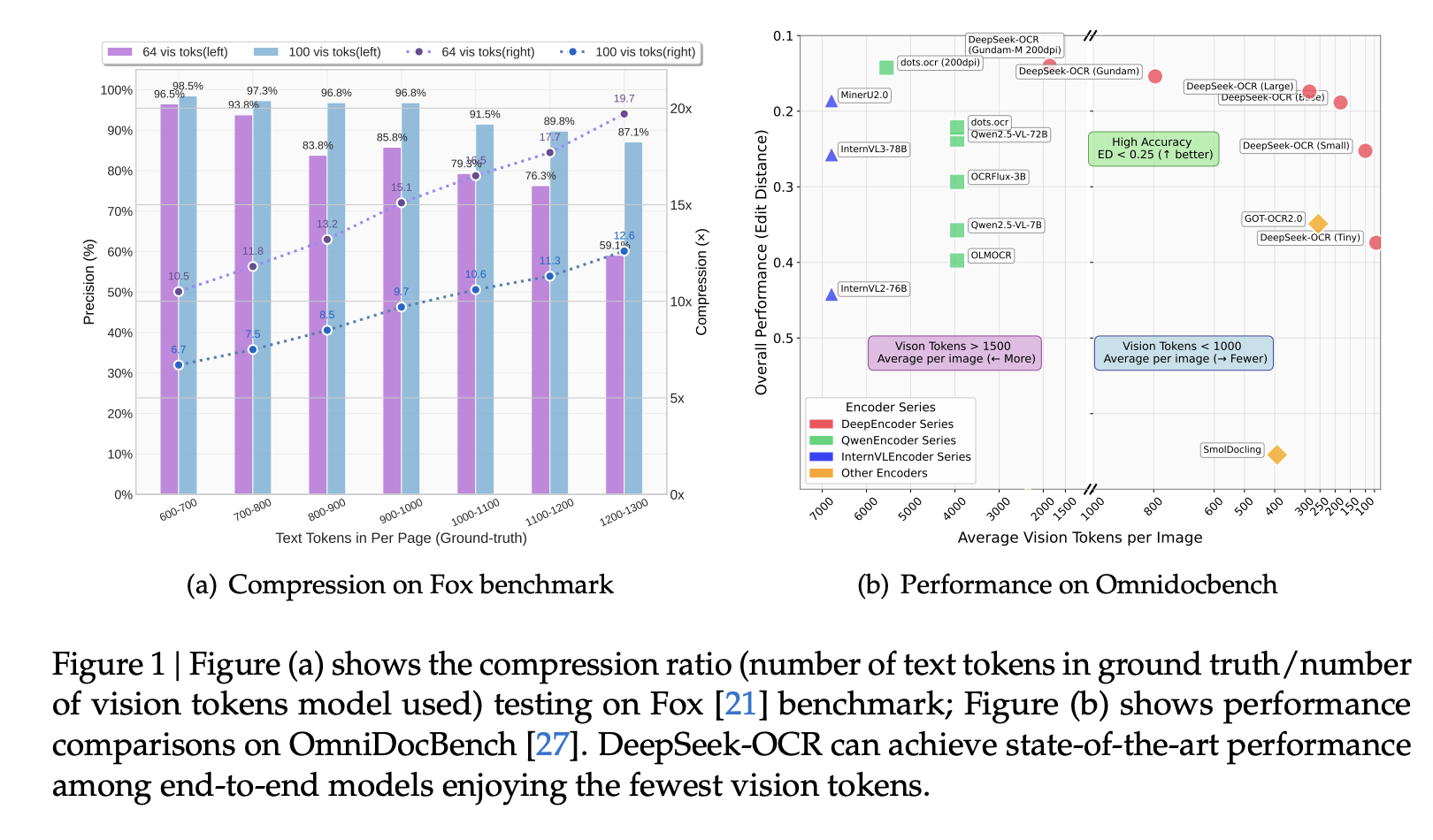
首先,我们对视觉文本 token 压缩率进行了全面的定量分析。如图 1(a) 所示,我们的方法在 Fox 基准测试中,针对不同文档布局,在 9-10 倍文本压缩下实现了 96% 以上的 OCR 解码精度,在 10-12 倍压缩下约为 90%,在 20 倍压缩下约为 60%(考虑到输出与真实文本之间的格式差异,实际精度甚至更高)。结果表明,紧凑型语言模型能够有效地学习解码压缩后的视觉表示,这意味着通过适当的预训练设计,更大的 LLMs 也能轻松获得类似的能力。
其次,我们引入了 DeepEncoder,这是一种新的架构,即使面对高分辨率输入,也能保持较低的激活内存和最少的视觉 token。它通过一个16倍卷积压缩器将窗口注意力编码器和全局注意力编码器组件串联起来。这种设计确保窗口注意力组件能够处理大量的视觉 token,而压缩器则在视觉 token 进入密集全局注意力组件之前对其进行缩减,从而实现有效的内存和 token 压缩。
第三,我们基于 DeepEncoder 和 DeepSeek3B-MoE 开发了 DeepSeek-OCR。如图 1(b) 所示,它在 OmniDocBench 端到端模型中实现了最先进的性能,同时使用了最少的视觉标记。此外,我们还赋予该模型解析图表、化学式、简单几何图形和自然图像的能力,以进一步增强其实用性。在生产环境中,DeepSeek-OCR 使用 20 个节点(每个节点配备 8 个 A100-40G GPU)每天可以为 LLM 或 VLM 生成 3300 万页数据。
总之,本文初步探索了将视觉模态作为高效文本信息处理媒介应用于 LLM 的可能性。通过 DeepSeekOCR,我们证明了视觉文本压缩能够在不同的历史上下文阶段实现显著的 token 缩减(7-20倍),为解决大语言模型中长上下文的挑战提供了一个有前景的方向。我们的定量分析为视觉语言模型(VLM)的 token 分配优化提供了经验指导,而我们提出的 DeepEncoder 架构则通过实际部署展现了其可行性。尽管本文以 OCR 作为概念验证,但这种范式为重新思考如何协同结合视觉和语言模态以提升大规模文本处理和智能体系统的计算效率开辟了新的可能性。
2.Related Works
2.1. Typical Vision Encoders in VLMs
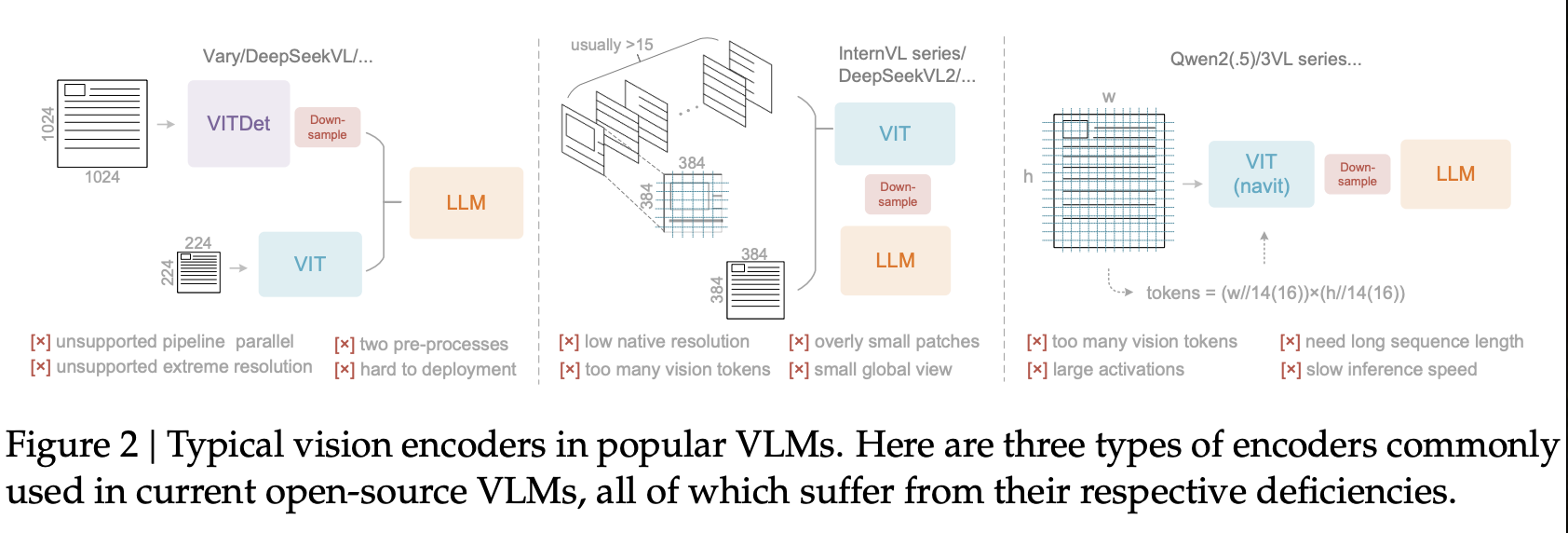
如图 2 所示,当前开源的视觉语言模型 (VLM) 主要采用三种类型的视觉编码器。第一种是双塔架构,以 Vary 为代表,它利用并行 SAM 编码器来增加高分辨率图像处理的视觉 token 参数。虽然这种方法提供了可控的参数和激活内存,但它也存在一些显著的缺点:它需要进行双重图像预处理,这使得部署变得复杂,并且在训练过程中难以实现编码器流水线的并行化。第二种是 tile-based 的方法,以 InternVL2.0 为代表,它将图像分割成小片进行并行计算,从而在高分辨率设置下减少激活内存。尽管这种方法能够处理极高的分辨率,但由于其通常较低的编码器原生分辨率(低于 512×512),导致大尺寸图像被过度分割,从而产生大量的视觉 token,因此存在明显的局限性。第三种类型是自适应分辨率编码,以 Qwen2-VL 为代表。它采用 NaViT 范式,通过基于图像块的分割直接处理完整图像,无需分块并行化。虽然这种编码器可以灵活处理各种分辨率,但由于激活内存消耗巨大,可能导致GPU内存溢出,因此在处理大型图像时面临巨大挑战;此外,序列打包在训练过程中需要极长的序列长度。过长的视觉 token 会减慢推理的预填充和生成阶段。
2.2 End-to-end OCR Models
光学字符识别(OCR),特别是文档解析任务,一直是图像到文本转换领域的研究热点。随着视觉语言模型(VLM)的发展,大量端到端OCR 模型涌现,通过简化OCR系统,从根本上改变了传统的流水线架构(该架构需要独立的检测和识别专家模型)。Nougat 首次在arXiv上将端到端框架应用于学术论文的 OCR,展示了模型在处理密集感知任务方面的潜力。GOT-OCR2.0 扩展了 OCR2.0 的范围,使其包含更多合成图像解析任务,并设计了一个兼顾性能和效率的OCR模型,进一步凸显了端到端OCR研究的潜力。此外,诸如Qwen-VL系列、InternVL 系列及其众多衍生模型等通用视觉模型也在不断增强其文档OCR能力,以探索密集视觉感知的边界。然而,当前模型尚未解决的一个关键研究问题是:对于一份包含1000个单词的文档,解码至少需要多少视觉 token?这个问题对于“一图胜千言”的研究原则具有重要意义。
3.Methodology
3.1 Architecture
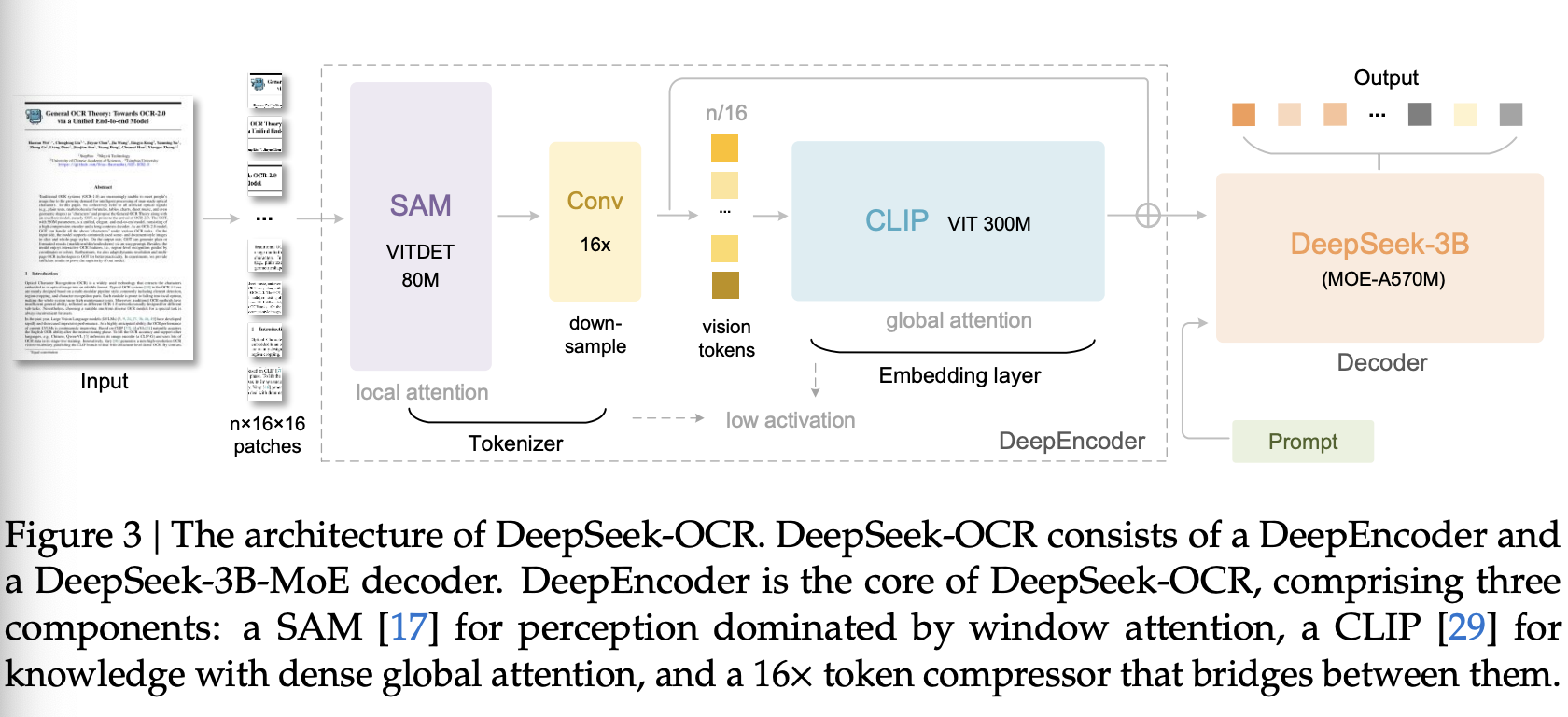
如图 3 所示,DeepSeek-OCR 采用统一的端到端 VLM 架构,由编码器和解码器组成。编码器(即 DeepEncoder)负责提取图像特征、分词以及压缩视觉表示。解码器则根据图像 token 和提示生成所需结果。DeepEncoder 的参数量约为 380M,主要由一个 80M 参数的 SAM-base 和一个 300M 参数的 CLIP-large 串联而成。解码器采用 3B MoE 架构,激活参数量为 570M。接下来,我们将深入探讨模型组件、数据工程和训练技术。
3.2 DeepEncoder
为了探索上下文光学压缩的可行性,我们需要一个具备以下特性的视觉编码器:1.能够处理高分辨率图像;2.在高分辨率下激活值低;3.所需的视觉 token 少;4.支持多种分辨率输入;5.参数数量适中。然而,正如2.1节所述,目前的开源编码器无法完全满足所有这些条件。因此,我们自行设计了一种新型视觉编码器,命名为 DeepEncoder。
3.2.1 Architecture of DeepEncoder
DeepEncoder 主要由两个组件构成:一个以窗口注意力机制为主的视觉感知特征提取组件,以及一个采用密集全局注意力机制的视觉知识特征提取组件。为了利用先前工作的预训练优势,我们分别使用 SAM-base(patch-size 16)和 CLIP-large 作为这两个组件的主要架构。对于 CLIP,我们移除了第一个图像块嵌入层,因为其输入不再是图像,而是来自前一个流水线的输出 token。在两个组件之间,我们借鉴了 Vary 的方法,使用一个两层卷积模块对视觉标记进行 16 倍下采样。每个卷积层的卷积核大小为 3,步长为 2,填充为 1,通道数从 256 增加到 1024。假设输入图像为 1024×1024,DeepEncoder 会将其分割成 1024/16×1024/16=4096 个图像块 token。由于编码器的前半部分主要由窗口注意力机制主导,且仅占用 80M 数据,因此激活值是可以接受的。在进入全局注意力机制之前,这 4096 个 token 会经过压缩模块,最终 token 数量变为 4096/16=256,从而使整体激活内存可控。
3.2.2 Multiple resolution support

假设我们有一张包含 1000 个光学字符的图像,我们想测试解码需要多少个视觉 token。这就要求模型支持可变数量的视觉 token。也就是说,深度编码器需要支持多种分辨率。
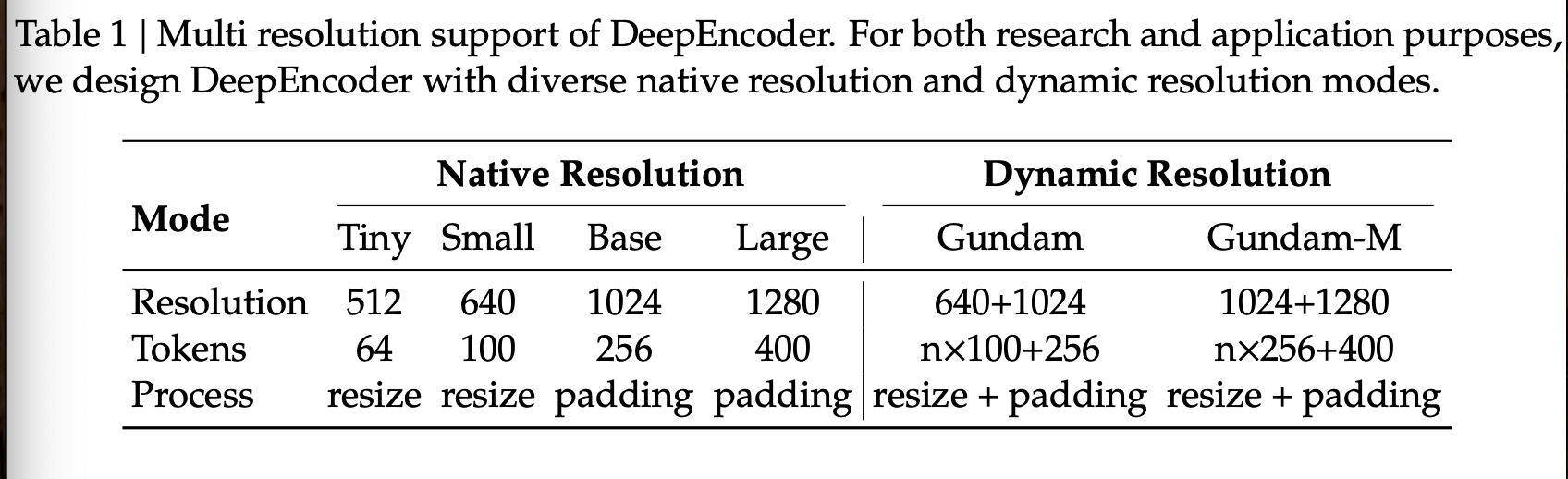
我们通过位置编码的动态插值满足上述要求,并设计了多种分辨率模式用于同步模型训练,从而使单个 DeepSeek-OCR 模型能够支持多种分辨率。如图 4 所示,DeepEncoder 主要支持两种输入模式:原始分辨率和动态分辨率。每种模式又包含多个子模式。
原始分辨率支持四种子模式:Tiny、Small、Base 和 Large,对应的分辨率和 token 数分别为 512×512 (64)、640×640 (100)、1024×1024 (256) 和 1280×1280 (400)。由于 Tiny 和 Small 模式的分辨率相对较小,为了避免浪费视觉 token,图像会直接调整原始形状的大小进行处理。对于 Base 和 Large 模式,为了保持原始图像的宽高比,图像会填充到相应的尺寸。填充后,有效视觉 token 的数量会少于实际视觉 token 的数量,计算公式如下:
其中 和 分别表示原始输入图像的宽度和高度。
动态分辨率可以由两个原生分辨率组成。例如,Gundam 模式由 个图块(局部视图)和一个 的全局视图组成。分块方法遵循 InternVL2.0。支持动态分辨率主要出于应用方面的考虑,尤其适用于超高分辨率输入(例如报纸图像)。分块是一种二级窗口注意力机制,可以有效减少激活内存。值得注意的是,由于我们采用了相对较大的原生分辨率,图像在动态分辨率下不会过度碎片化(图块数量控制在 2 到 9 之间)。Gundam 模式下 DeepEncoder 输出的视觉标记数量为:,其中 为图块数量。对于宽度和高度均小于 640 的图像, 设置为 0,即高达模式将降级为基础模式。
Gundam 模式与四种原生分辨率模式一起训练,以实现一个模型支持多种分辨率的目标。需要注意的是,Gundam-master 模式(1024×1024 局部视图 + 1280×1280 全局视图)是通过对已训练好的 DeepSeekOCR 模型进行持续训练而获得的。这样做主要是为了均衡负载,因为高达大师模式的分辨率过高,如果同时训练会降低整体训练速度。
3.3 The MoE Decoder
我们的解码器采用 DeepSeekMoE,具体来说是 DeepSeek-3B-MoE。在推理过程中,该模型激活了 64 个路由专家中的 6 个和 2 个共享专家,激活参数约 570M。3B DeepSeekMoE 非常适合领域中心化(对我们而言是 OCR)的 VLM 研究,因为它既具备 3B 模型的表达能力,又拥有500M 参数的小型模型的推理效率。
解码器根据 DeepEncoder 压缩后的潜在视觉 token 重建原始文本表示,如下所示:
其中 是来自 DeepEncoder 的压缩潜在(视觉)token, 是重构的文本表示。函数 表示一个非线性映射,可以通过类似 OCR 的训练方式被紧凑型语言模型有效地学习。可以合理推测,LLM 通过专门的预训练优化,将展现出对这些能力更自然的整合。
3.4 Data Engine
我们为 DeepSeek-OCR 构建了复杂多样的训练数据,包括 OCR 1.0 数据(主要包含场景图像 OCR 和文档 OCR 等传统 OCR 任务)、OCR 2.0 数据(主要包含复杂人工图像的解析任务,例如常用图表、化学式和平面几何解析数据)以及通用视觉数据(主要用于将某些通用图像理解能力注入 DeepSeek-OCR 并保留通用视觉接口)。
3.4.1 OCR 1.0 data

文档数据是 DeepSeek-OCR 的首要任务。我们从互联网上收集了 3000 万页涵盖约 100 种语言的PDF数据,其中中文和英文约占2500万页,其他语言约占500万页。针对这些数据,我们创建了两种类型的标注:粗略标注和精细标注。粗略标注直接使用 fitz 从完整数据集中提取,旨在训练模型识别光学文本,尤其是在少数民族语言中。精细标注包括中文和英文各200万页,使用高级布局模型(例如PP-DocLayout)和 OCR 模型(例如MinuerU 和GOT-OCR2.0)进行标注,以构建检测和识别交错的数据。对于少数民族语言,在检测部分,我们发现布局模型具有一定的泛化能力。在识别部分,我们使用 fitz 生成小块数据来训练 GOT-OCR2.0 模型,然后使用训练好的模型对经过布局处理的小块数据进行标注,并采用模型飞轮生成 60 万个数据样本。在 DeepSeek-OCR 的训练过程中,我们使用不同的提示语来区分粗略标注和精细标注。精细标注的图像-文本对的真实标签如图 5 所示。此外,我们还收集了 300 万个单词数据,通过直接提取内容构建了无需布局的高质量图像-文本对。这些数据主要适用于公式和 HTML 格式的表格。另外,我们还选取了一些开源数据作为补充。
对于自然场景 OCR,我们的模型主要支持中文和英文。图像数据来源于LAION 和Wukong,并使用 PaddleOCR 进行标注,中文和英文各有1000万个数据样本。与文档 OCR 类似,自然场景 OCR 也可以通过提示控制是否输出检测框。
3.4.2 OCR 2.0 data

根据 GOT-OCR2.0 的规范,我们将图表、化学式和平面几何解析数据统称为 OCR 2.0 数据。对于图表数据,我们参考 OneChart 的方法,使用 pyecharts 和 matplotlib 渲染 1000 万张图像,主要包括常用的折线图、柱状图、饼图和复合图。我们将图表解析定义为图像到 HTML 表格的转换任务,如图 6(a) 所示。对于化学式,我们使用 PubChem 的 SMILES 格式作为数据源,并使用 RDKit 将其渲染成图像,构建了 500 万个图像-文本对。对于平面几何图像,我们参考 Slow Perception 的方法进行生成。具体来说,我们使用感知标尺大小为 4 来对每个线段进行建模。为了增加渲染数据的多样性,我们引入了几何平移不变数据增强,即将相同的几何图像在原始图像中进行平移,使其对应于坐标系中心位置绘制的相同真实值。基于此,我们构建了总共 100 万个平面几何解析数据,如图 6(b) 所示。
3.4.3 General vision data
DeepEncoder 可以受益于 CLIP 的预训练成果,并且拥有足够的参数来融合通用的视觉知识。因此,我们也为 DeepSeek-OCR 准备了一些相应的数据。参照 DeepSeek-VL2,我们生成了与图像描述、图像检测和场景定位等任务相关的数据。需要注意的是,DeepSeek-OCR 并非通用的视觉语言模型,这部分数据仅占总数据的 20%。我们引入这类数据主要是为了保持通用的视觉接口,以便未来对我们的模型和通用视觉任务感兴趣的研究人员能够方便地开展相关工作。
3.4.4 Text-only data
为了确保模型的语言能力,我们引入了10%的内部纯文本预训练数据,所有数据均处理至 8192 个 token 长度,这与 DeepSeek-OCR 的序列长度一致。总而言之,在训练DeepSeek-OCR时,OCR数据占70%,通用视觉数据占20%,纯文本数据占10%。
3.5 Training Pipelines
我们的训练流程非常简单,主要包含两个阶段:a) 独立训练 DeepEncoder;b) 训练 DeepSeek-OCR。需要注意的是,Gundam-master 模式是通过在预训练的 DeepSeek-OCR 模型上继续训练 600 万采样数据而获得的。由于训练流程与其他模式相同,因此我们在此省略详细描述。
3.5.1 Training DeepEncoder
参照 Vary 的方法,我们采用紧凑型语言模型,并使用下一个 token 预测框架训练 DeepEncoder。在此阶段,我们使用了上述所有 OCR 1.0 和 2.0 数据,以及从 LAION 数据集中抽取的 1 亿个通用数据。所有数据均使用 AdamW 优化器和余弦退火调度器进行训练,训练周期为 2 个 epoch,批大小为 1280,学习率为 5e-5。训练序列长度为 4096。
3.5.2 Training DeepSeek-OCR
DeepEncoder 准备就绪后,我们使用3.4节中提到的数据来训练DeepSeek-OCR模型。整个训练过程在 HAI-LLM 平台上进行。整个模型采用流水线并行(PP)技术,并分为4个部分,其中DeepEncoder占2个部分,解码器占2个部分。对于DeepEncoder,我们将SAM和压缩器视为视觉 tokenizer,将其放置在PP0中并冻结其参数;同时将CLIP部分视为输入嵌入层,并将其放置在PP1中,训练时权重不冻结。对于语言模型部分,由于DeepSeek3B-MoE有12层,我们在PP2和PP3中各放置6层。我们使用20个节点(每个节点配备8个A100-40G GPU)进行训练,数据并行度(DP)为40,全局批大小为640。我们使用AdamW优化器,采用基于步长的调度器,初始学习率为3e-5。对于纯文本数据,训练速度为每天 90B 个 token;而对于多模态数据,训练速度为每天 70B 个 token。